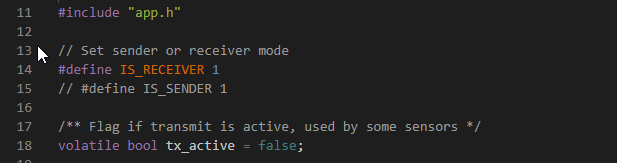
I’m programming a RAK11720 with the RUI3 for LoRa P2P. For this application, I’m using two RAK11720 devices with the RUI.
One device only listens and sends a reception confirmation. That device isn’t having any problems; the problem lies with the device that sends the message.
The sequence is as follows:
-
Sends a LoRa packet.
-
Enters receive mode.
-
Waits for a while. If it doesn’t receive a confirmation,
-
Re-sends the message.
-
Enters receive mode.
-
Waits for a while. If it doesn’t receive a confirmation,
-
Goes to sleep.
-
When it wakes up, it sends the message again and repeats the process.
**If it receives the message, it sends a reception confirmation, goes to sleep, and repeats the process.
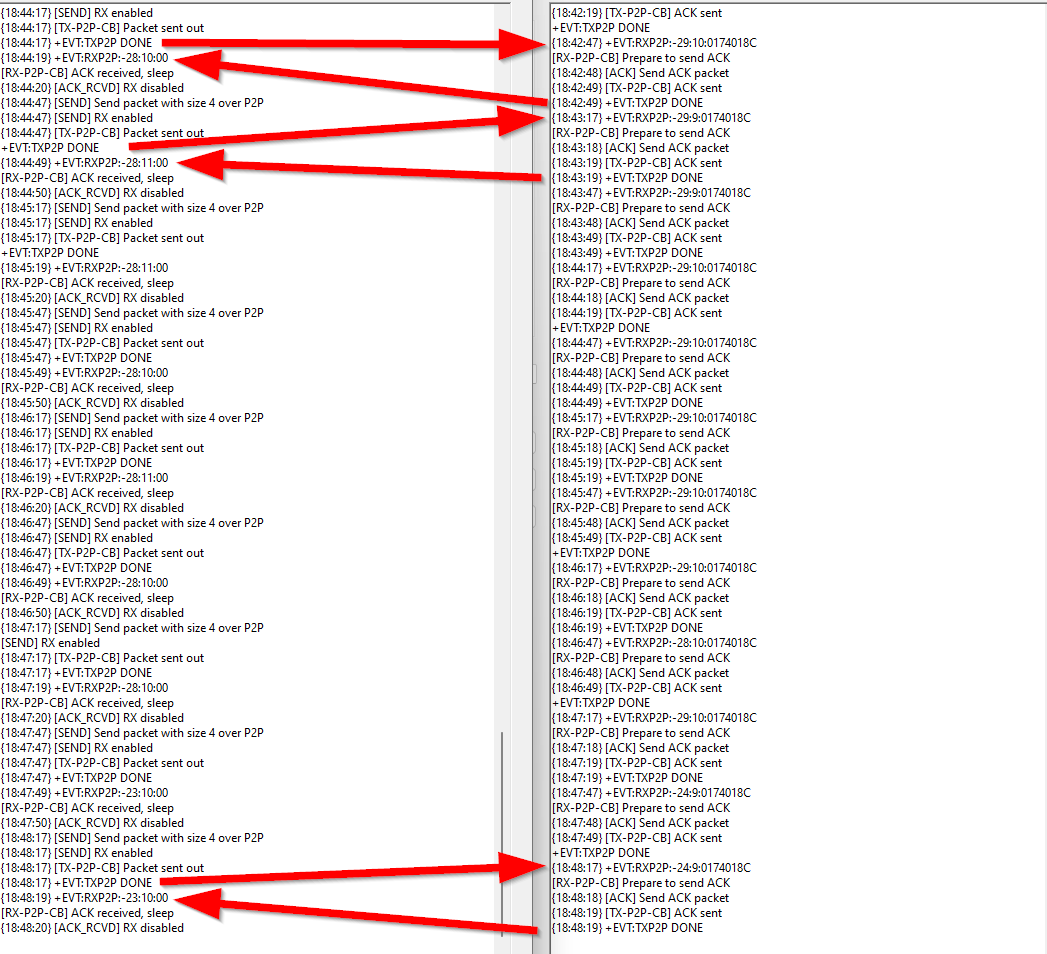
The device will correctly complete about three sequences. Each time it sends a message, the send callback is executed. api.lora.registerPSendCallback(send_cb);
But at a certain point, when it goes to sleep and wakes up, it no longer executes any of the callbacks, neither the send nor the receive callback. api.lora.registerPRecvCallback(recv_cb);
The problem is that I depend on these callbacks executing because I activate crucial flags for my application in the send callback.
I’ve been dealing with this error for about a year, and I was able to identify that the callbacks aren’t executing. I implemented traces to determine this.
I tried re-registering the send and receive callbacks every time the device wakes up. I tried doing it programmatically and even created an AT command that does it. Nothing works; it only works after restarting the device. I really wanted to avoid restarting the processor because battery consumption is critical for my application. I’m currently using RUI3 version 4.2.3 and I’ve also tried previous versions without WDT implemented.
My questions are as follows:
-
I’m considering replacing the RAK11720 with a RAK11160 with STM32 or with a RAK4630. Is it possible that the callback problem occurs specifically with Apollo 3 and not with STM32 or Nordic?
-
My intention is to continue using the RUI3 API since it’s quite quick to implement, so I wanted to ask if these errors only happen with Apollo 3 or if it’s a general problem with RUI3.
-
api.system.sleep.all(). api.system.lpm.set(). The other issue is whether putting the device to sleep with this instruction is what causes the callback bug, or if it’s better to use these instructions, and if there’s any difference compared to using
api.system.sleep.lora(). -
I can set a guard condition to restart with the following instruction:
api.system.reboot(); or restart with the WDT that’s now in the RUI (it didn’t exist before). My question is, which is more energy-efficient? -
I have the option of implementing an external WDT.
I would appreciate any help and information, because if this is a widespread problem with RUI3, we as a team are considering not using RUI3.